Multi-Cloud Without the Theater: Where Portability Actually Pays
Multi-cloud is one of the most overprescribed strategies in enterprise architecture. The idea sounds prudent, the slide builds itself, and the cost falls quietly on engineering teams who absorb the complexity for years afterward. Some real cases exist where multi-cloud pays. They are narrower than the typical board deck implies.
The gap between rhetoric and practice is large. Flexera's 2024 State of the Cloud Report found that 89 percent of enterprises describe themselves as multi-cloud, but the same survey shows that the majority of workloads in those organizations run on a single primary provider with secondary clouds hosting isolated estates. "Multi-cloud" in the wild is overwhelmingly the result of acquisitions, shadow IT, and capability-driven workload placement, not the deliberate, portable architecture the strategy decks describe. We've found that distinction matters enormously when the conversation moves from intent to invoice.
The four reasons usually cited, and which hold up
Almost every multi-cloud strategy is justified by one of four arguments. Examined honestly:
- "Avoid vendor lock-in." The weakest argument. The cost of staying portable across hyperscalers is paid every quarter; the cost of being locked in is paid once, at renegotiation, and is rarely as severe as the portability tax. Hyperscalers have strong commercial incentives to retain customers; they do not need to be punished into reasonable pricing. The dirty secret is that committing harder to one cloud usually produces better economics than hedging across two: AWS Savings Plans and Azure Reserved Instances routinely deliver 40 to 72 percent discounts off on-demand rates for workloads with three-year commitments, and those discounts evaporate the moment workloads are split to preserve optionality.
- "Negotiating use." Real, but achievable with credible-threat multi-cloud rather than active multi-cloud. A workload you could move in six months gives you the same use as one running in production on two clouds, at a fraction of the cost. Procurement leaders we work with have learned to walk into renewals with a costed migration plan rather than a live secondary footprint; the plan is cheaper to maintain and equally persuasive.
- "Disaster recovery." Mostly weak. Hyperscaler region-level outages are rare; multi-region within one cloud is dramatically simpler than multi-cloud and covers 95 percent of the disaster scenarios that matter. AWS publishes a composite uptime SLA of 99.99 percent for multi-AZ services, which translates to roughly 52 minutes of permitted downtime per year. For most enterprises, the residual risk that justifies a second hyperscaler is smaller than the operational risk introduced by running one.
- "Service capability gaps." The strongest argument. Specific services,BigQuery for some analytics workloads, Bedrock or Vertex for some AI workloads, Azure for AD-integrated and Microsoft 365-adjacent workloads,are genuinely best-of-breed. Choosing the right cloud per workload is sound; trying to make every workload run on every cloud is not.

Three multi-cloud patterns that actually pay
The patterns where we see real ROI are narrower than most strategies admit:
- Workload-aligned multi-cloud. Different workloads run on different clouds based on capability fit, with no expectation of portability between them. Most successful "multi-cloud" enterprises are actually this pattern, even when their architecture documents claim something more ambitious. Data science on GCP, productivity and identity on Azure, customer-facing services on AWS, with well-defined integration seams between them. The portability boundary is the API contract, not the runtime.
- Edge-and-core split. Edge workloads on a provider with strong edge presence (Cloudflare, Fastly, AWS CloudFront), core workloads on a hyperscaler. The interface between them is well-defined and the portability boundary is the edge layer. Cloudflare's network reaches over 330 cities globally, which is a footprint no single hyperscaler matches for last-mile latency, and the operational model,configuration as code at the edge, stateless workers, origin pull from the core,keeps the seam clean.
- Regulated and unregulated split. A specific subset of workloads must run on a specific cloud or sovereign region for regulatory reasons; the rest of the estate runs wherever capability fit drives. Treat this as workload-aligned multi-cloud with extra audit overhead. The EU's Digital Operational Resilience Act (DORA), which became enforceable in January 2025, has pushed many financial institutions toward this pattern explicitly, requiring documented exit strategies and concentration-risk analysis for ICT third parties. DORA does not require multi-cloud; it requires that you can credibly leave a cloud. Those are different problems with different cost structures.
The patterns that do not pay
Three patterns reliably underperform.
The first is active-active multi-cloud for general-purpose web workloads, where the operational tax is permanent and the benefit is theoretical. Cross-cloud egress alone tends to run 5 to 9 cents per gigabyte at typical commit tiers, and a chatty active-active service burns that line item continuously. We've audited estates where cross-cloud data transfer accounted for 12 to 18 percent of total cloud spend, with no measurable resilience benefit beyond what a well-designed multi-region single-cloud deployment already provided.
The second is Kubernetes-as-portability-layer. The promise,write once, run on any cloud,runs aground on the lower layers. Storage classes, load balancer integrations, IAM bindings, secrets management, and network policy implementations all leak hyperscaler-specific behavior into Helm charts and operator configurations. Kubernetes is an excellent compute abstraction; it is not a portability solvent. Teams that adopt it expecting the latter spend two to three years discovering otherwise.
The third is "we will pick the cheaper cloud per workload," which assumes a level of cost transparency and engineering elasticity most organizations do not have. Spot pricing differentials between AWS, Azure, and GCP for equivalent instance types fluctuate by single-digit percentages week to week. Capturing that arbitrage requires automated workload mobility that almost nobody has actually built, and the engineering investment to build it dwarfs the savings for at least the first five years.
A counter-take: deeper lock-in is often the right answer
The consensus in CIO forums and analyst briefings is that lock-in is a risk to be mitigated. We disagree, at least for the median enterprise. The unspoken alternative to lock-in is not freedom; it is mediocrity. Teams that fully commit to one cloud's managed services,DynamoDB instead of self-hosted Cassandra, Cloud Run or Lambda instead of Kubernetes, BigQuery instead of a vendor-neutral lakehouse,ship faster, operate smaller platform teams, and produce systems that are simpler to reason about. The lock-in is real. So is the productivity dividend.
The right framing is not "how do we avoid lock-in" but "what is the price of the lock-in we're choosing, and is it worth it?" In our experience, deep commitment to AWS or Azure or GCP managed services typically returns 2 to 4x the engineering velocity of a portable equivalent, sustained over the life of the system. That is a trade most organizations should take and few are willing to admit they are taking.
The hidden tax
The cost of multi-cloud is rarely the infrastructure spend. It is the engineering cognitive load: every team must understand two IAM models, two networking models, two observability stacks, two cost models. The marginal hire on a multi-cloud team is 20 to 40 percent less productive in their first year than the same hire on a single-cloud team, because the surface area they must learn is correspondingly larger.
The tax compounds in less visible ways. Security reviews take longer because threat models must cover two control planes. Incident response runbooks bifurcate. Compliance evidence collection roughly doubles, because SOC 2 and ISO 27001 auditors want to see controls operating in each environment. Procurement and FinOps functions need expertise in two billing taxonomies that share almost no vocabulary. We've seen platform engineering org charts grow by six to ten roles purely to service the second cloud, with no corresponding increase in product velocity. That is the line item that should appear on the board deck and almost never does.
A also a talent-market effect. Engineers who are fluent in one cloud's managed services are a known commodity; engineers who are genuinely fluent in two are rare and command 15 to 25 percent salary premiums in our hiring data. Most "multi-cloud teams" are actually two single-cloud subteams stapled together, with the integration work falling on a small group of senior architects who become single points of failure.
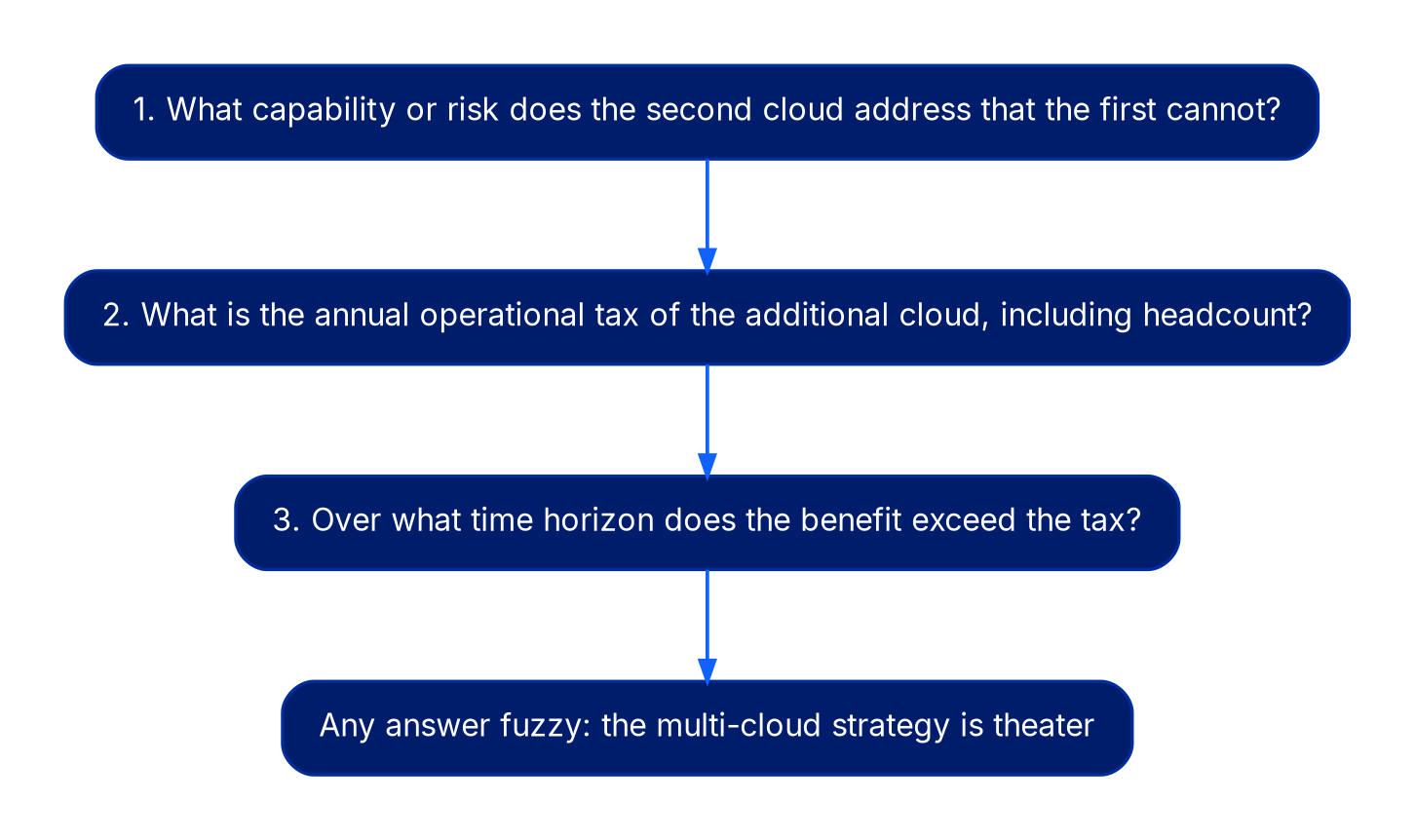
How to evaluate honestly
The right test for any proposed multi-cloud move is to ask three questions: What specific capability or risk does the second cloud address that cannot be addressed within the first? What is the annual operational tax of the additional cloud, including the headcount needed to support it? Over what time horizon does the benefit exceed the tax? If any of those three answers is fuzzy, the multi-cloud strategy is theater.
We push clients to write the answers down with numbers. "Resilience" is not an answer; "we need recovery time objective under 15 minutes for the payments service, and our regulator has rejected single-cloud multi-region as sufficient evidence" is an answer. "Negotiating use" is not an answer; "our AWS spend is $40M annually and a credible 18-month migration plan to GCP gives us roughly $4M to $6M of renewal use based on prior negotiations" is an answer. The discipline of quantification kills most multi-cloud proposals before they reach implementation, which is the point.
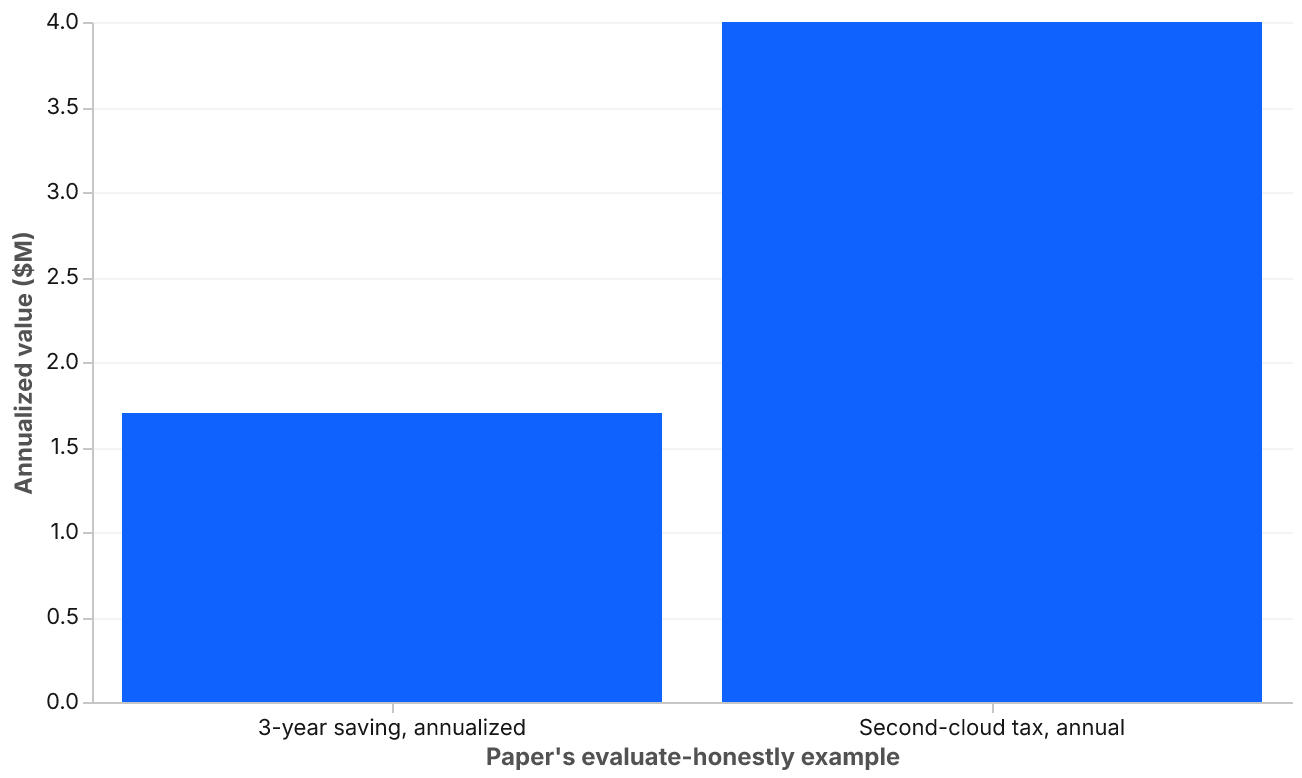
The questions also surface a useful asymmetry: the benefits of multi-cloud are usually one-time or episodic (a successful renegotiation, a rare regional failure, a regulatory check passed), while the costs are continuous. Any honest evaluation has to discount the benefits accordingly. A $5M renewal saving every three years is a $1.7M annualized benefit. If the operational tax of the second cloud is $4M annually, the math is not close.
The bottom line
Pick clouds for workloads, not workloads for clouds. Multi-cloud is a tool, not a strategy. Use it where the capability or risk math is clear; resist it everywhere else.
The board-deck version of multi-cloud,portable workloads, active-active deployments, cloud-agnostic platforms,is almost always wrong for almost every enterprise. The practitioner version,deliberate workload placement on the cloud whose managed services fit best, with clean integration seams and a documented exit plan rather than a live secondary footprint,is almost always right. The two patterns share a name and almost nothing else.
The organizations getting the most out of cloud are not the ones with the most clouds. They are the ones who have made fewer, better commitments and invested the saved engineering capacity in the products their customers actually pay for. That is an unfashionable position to put in a strategy document. It is also, in our experience, the one that pays.