Cloud Cost Discipline: A 30/60/90 Plan for Mid-Market Buyers
Most mid-market cloud bills are 25 to 40 percent inefficient. A focused ninety-day plan to recover that spend without a refactor.
Cloud cost optimization has become a crowded category, but most mid-market buyers do not need a platform, they need a sequenced plan. The right ninety days will recover more spend than the next twelve months of dashboards. The pattern we've seen across mid-market engagements is consistent: the savings exist, the data exists to find them, and the engineering capacity exists to act. What is usually missing is a forcing function and a sequence.
Why mid-market is the sweet spot for fast wins
Enterprises with eight or nine-figure cloud spend have already engaged Anaplan, Apptio, or a hyperscaler enterprise discount program. Mid-market buyers, roughly $500K to $5M in annual cloud spend, sit in a band where the unit economics of those tools rarely pencil out, but where 25 to 40 percent of spend is recoverable with disciplined manual work. That gap is where focused engagements deliver the highest ROI.
The macro picture reinforces the opportunity. Flexera's 2024 State of the Cloud Report puts self-reported cloud waste at 27 percent on average, and respondents consistently estimate they could cut another 10 to 20 percent with better governance. Gartner has separately projected worldwide end-user public cloud spend to exceed $675 billion in 2024, which means even modest waste percentages translate to large absolute dollars at the company level. Mid-market buyers feel that math acutely because cloud is now typically their second or third largest operating expense, behind payroll and sometimes ahead of real estate.
A counter-take worth airing: the FinOps Foundation orthodoxy treats tooling investment as a precondition for maturity. We disagree at this size band. For a buyer under $5M in annual spend, a competent engineer with read access to the billing console and a spreadsheet will surface 80 percent of the savings a $150K platform license would. Buy the tool when you have the spend to justify the seat cost; until then, do the work.
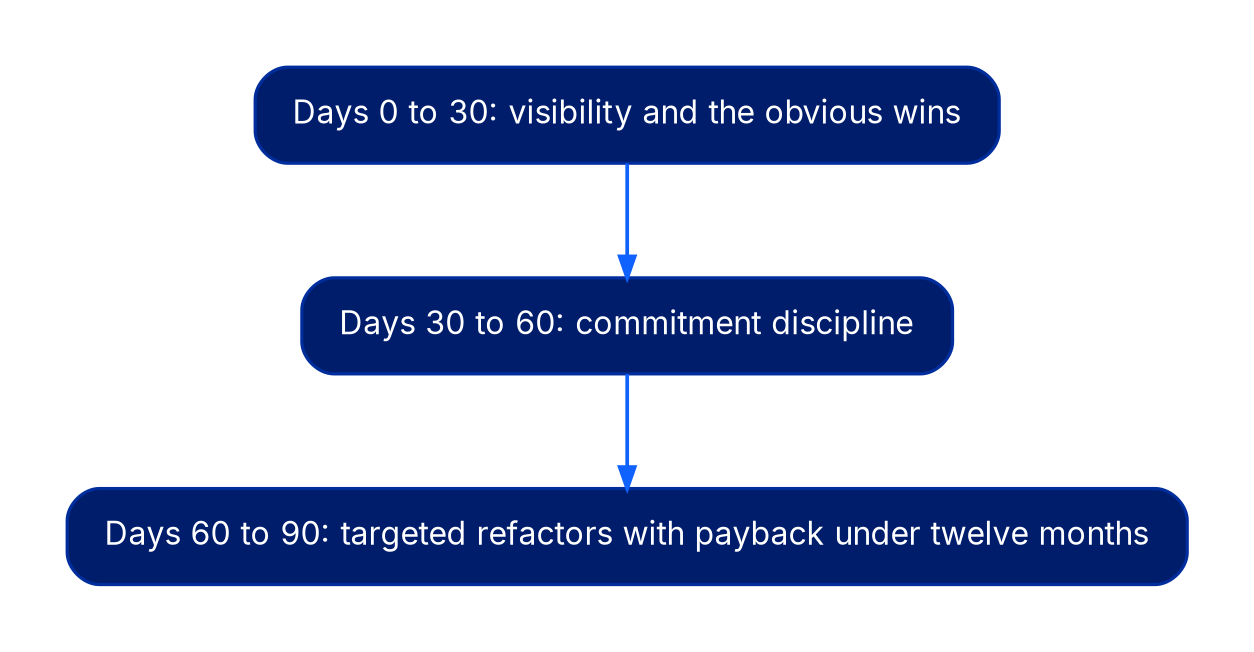
Days 0 to 30: visibility and the obvious wins
The first month is not the time to refactor anything. It is the time to see what you actually run. Tag coverage above 90 percent across compute, storage, and data services is the only prerequisite that matters. Without it, every subsequent decision is a guess. Once tagging is in place, the obvious wins surface within days: idle non-production environments, oversized instances running at 5% utilization, snapshots and unattached volumes from departed engineers, and overprovisioned database instances sized for a launch that happened three years ago.
In our work, the single highest-yield query in week one is a join of compute utilization data against the asset inventory: any instance with sustained CPU below 10 percent over a 14-day window is a candidate for downsizing or termination. AWS exposes this directly through the Compute Optimizer recommendation engine, and Azure and GCP have functional equivalents in Advisor and Recommender respectively. The data is free; acting on it is what separates buyers who recover spend from buyers who only describe it.
Two practical traps to avoid in this window. First, do not let engineering teams self-certify that an instance is "needed" without quantitative justification. The right default is termination after a 30-day quarantine, with the burden of proof on the team that wants to keep it. Second, do not chase storage class transitions before you have lifecycle policies in place; moving cold data to a cheaper tier without a policy guarantees you will move it again next year.
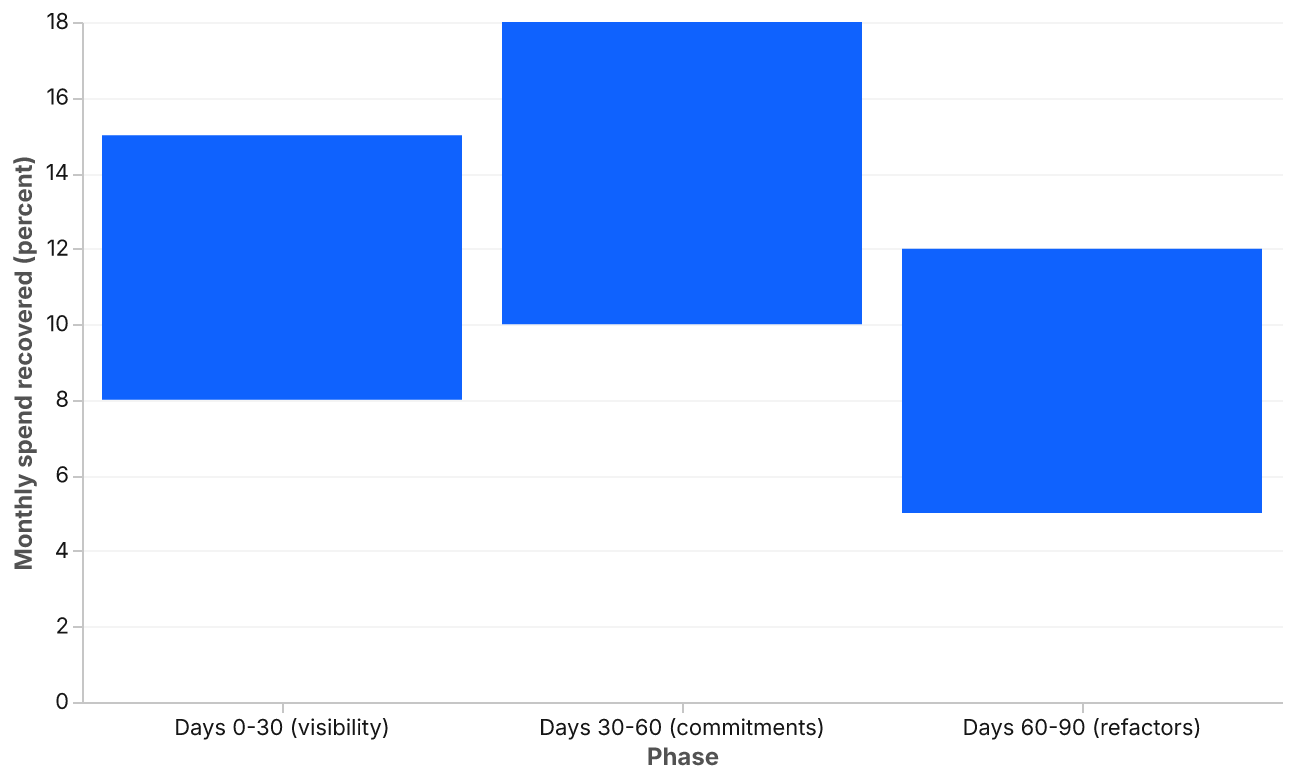
Expect to recover 8 to 15 percent of monthly spend in this window with no architectural change.
Days 30 to 60: commitment discipline
The second month is about commitment posture. Reserved instances, savings plans, and committed-use discounts are not the same instrument across hyperscalers, and treating them interchangeably leaves money on the table. AWS Compute Savings Plans cover Lambda and Fargate in addition to EC2 and offer up to 66 percent off on-demand pricing on three-year all-upfront terms. Azure Reserved VM Instances and Savings Plans for Compute have different scope rules, and GCP's Committed Use Discounts split between resource-based and spend-based commitments with materially different flexibility profiles. A blanket commitment policy across clouds is malpractice.
The right approach is to build a commitment ladder: lock the floor of your steady-state load (typically 60 to 70 percent of compute) on three-year commitments, layer one-year commitments over the next 15 to 20 percent, and let the top of the curve run on-demand. Spot capacity belongs in batch and stateless workloads, not as a primary commitment lever for mid-market buyers who lack the engineering bench to handle interruptions cleanly.
A common counter-argument from finance teams: "Three-year commitments are too risky given how fast our architecture changes." We have heard this dozens of times and the data rarely supports it. Steady-state compute floors at mid-market companies are remarkably stable; the volatility lives in the top 20 percent of the load curve, which is exactly where we recommend leaving on-demand headroom. The risk of over-committing is real but bounded; the risk of under-committing is paying full retail every month indefinitely.
Expect another 10 to 18 percent reduction here, depending on how undisciplined commitments were before.
Days 60 to 90: targeted refactors with payback under twelve months
The final month is where you allow architectural change, but only where the payback is clear and short. Three patterns dominate:
- S3 Intelligent-Tiering and equivalents. Mid-market data estates almost always have tens of terabytes of cold data sitting on hot storage tiers. AWS publishes S3 Intelligent-Tiering pricing that automatically transitions objects across access tiers; the migration is operationally trivial and saves 50 to 70 percent on the affected data within a billing cycle. The equivalent on Azure is Blob Storage lifecycle management, and on GCP it is Autoclass.
- Database right-sizing with read replicas. Many mid-market RDS or Cloud SQL instances are sized for peak read load that should sit on replicas. Splitting reads typically lets you drop the primary by one to two instance classes, which on a db.r6i.4xlarge baseline is roughly $1,400 per month per dropped class in us-east-1 on-demand pricing.
- NAT gateway and inter-AZ traffic audit. The single most overlooked line item in mid-market AWS bills. NAT gateway data processing charges accrue at $0.045 per GB on top of the hourly charge, and a chatty service mesh can drive that to five-figure monthly bills before anyone notices. A weekend of VPC endpoint deployment routinely takes those costs to four-figure. Inter-AZ traffic at $0.01 per GB each way is a smaller line individually but adds up fast in any architecture that does cross-AZ chatter without affinity routing.
A fourth pattern worth flagging, though we treat it as a stretch goal rather than a 90-day commitment: Graviton or equivalent ARM migration for stateless services. The price-performance gain is real, but the validation work on third-party dependencies usually exceeds the 30-day window we have left. Park it for the post-engagement roadmap.
What does not belong in a ninety-day plan
Avoid the temptation to bundle migrations, container modernization, or multi-cloud projects into the cost program. Each of those is worth doing in isolation when the business case is right; bundling them with a cost initiative dilutes accountability and stretches the timeline past the point where executive attention holds.
We are particularly skeptical of multi-cloud as a cost lever for mid-market buyers. The theoretical price arbitrage rarely survives contact with egress charges, duplicated tooling, and the engineering tax of maintaining parity. If a buyer is on a single hyperscaler today, the right answer in 90 percent of cases is to negotiate harder with that hyperscaler, not to spin up a second one. The Enterprise Discount Program threshold at AWS, for example, becomes negotiable well below the published guidance for buyers who can credibly commit to growth.
Similarly, FinOps tooling procurement does not belong in this window. The discipline you build manually in 90 days informs what tooling you actually need, and buyers who buy tools first invariably end up with shelfware that codifies whatever taxonomy the vendor preferred.
Sustaining the gain
The hardest part of cost work is not finding the savings, it is keeping them. Without an owner accountable to a unit-cost metric (cost per active user, cost per transaction, cost per gigabyte processed), the savings erode within two quarters. The most durable programs we see assign a single FinOps lead to that metric and review it in the same operating cadence as engineering velocity and reliability.
The reporting structure matters more than the title. A FinOps lead who reports into finance will optimize for budget variance and miss engineering-driven waste; a lead who reports into engineering will under-prioritize commitment posture. The pattern that works is a dotted-line into both, with a hard line into whichever function the CFO and CTO jointly trust to enforce decisions. In practice that is most often the platform or infrastructure engineering organization, with finance providing the unit-cost framing.
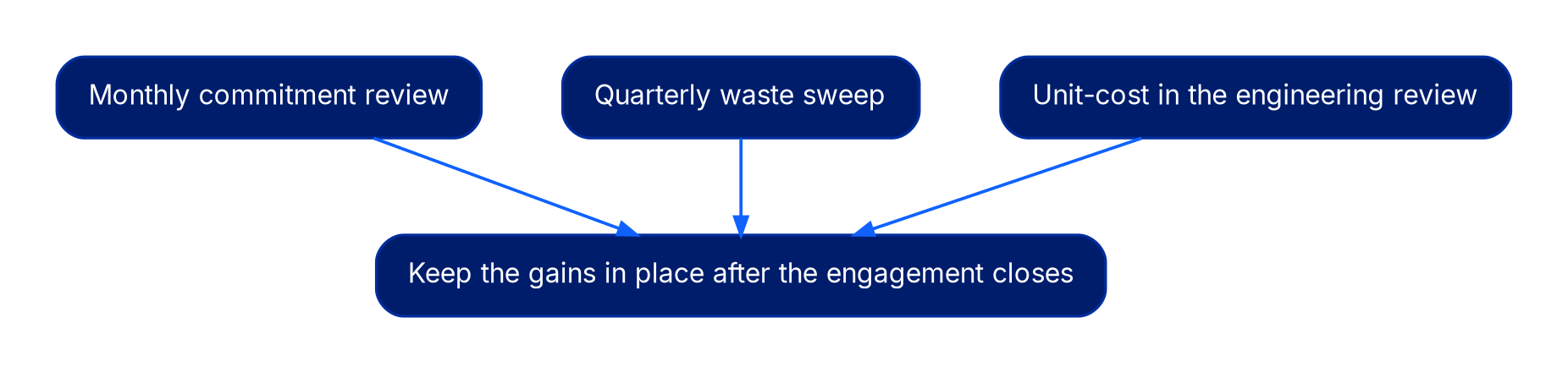
Three lightweight practices keep the gains in place once the engagement closes:
- Monthly commitment review. A 30-minute meeting to confirm utilization on existing commitments and decide whether to extend the ladder. Anything less frequent and expirations slip.
- Quarterly waste sweep. The same Day 0-30 queries, run on a calendar. Idle resources accumulate continuously; the only question is whether you catch them in the quarter or the year.
- Unit-cost in the engineering review. If the cost per transaction is not on the same dashboard as p99 latency, engineers will optimize the latter at the expense of the former. Putting both numbers in front of the same audience is the single highest-use governance change a mid-market buyer can make.
The bottom line
Mid-market cloud cost optimization is a tractable, repeatable engagement. A disciplined ninety days will deliver returns that no platform license can match, provided the organization has the appetite to enforce the commitments after the consultants leave. The combined arithmetic from the three windows, 8 to 15 percent in the first month, 10 to 18 percent in the second, and another 5 to 12 percent from targeted refactors, lands most buyers in the 25 to 40 percent recovery band that the opening of this paper claims. That is not a forecast; it is what the work actually produces when sequenced correctly.
The buyers who get the most out of this approach share three traits: a CFO who will sign a three-year commitment without flinching, a head of engineering who will defend termination defaults against team-by-team appeals, and a single accountable owner for unit cost after the engagement ends. Where any of those three are missing, the savings still appear in month three, and most of them still disappear by month nine. Where all three are present, the discipline compounds, and the next year's cloud bill grows with the business rather than ahead of it.