Data contract enforcement patterns that hold under production pressure
Almost every data platform team has documented a data contract. Fewer have wired enforcement that actually fires when a producer ships a breaking schema change on a Tuesday afternoon under release pressure. The distinction matters: a data contract that is not enforced is a wiki page with extra steps.
We have spent the last three years helping engineering teams close this gap. The pattern repeats itself. Teams write the contracts. They publish them to a catalog. They declare the data governance program a success. Then a producer adds a nullable column that downstream models assume is always populated, and an executive dashboard goes dark on a Friday morning. The contracts existed. They were not enforced.
This paper is about enforcement: the mechanisms, the layering, and the ownership model that makes enforcement stick under real production conditions.
Why documented contracts fail at the seam
The tooling to enforce contracts has existed for years. Confluent's Schema Registry has rejected incompatible Avro schemas since 2015. dbt model contracts shipped in dbt-core 1.5 in 2023, giving SQL transformation teams a native way to assert column types and not-null constraints as part of the build. The Open Data Contract Standard, now maintained under the Linux Foundation's Bitol project, provides a vendor-neutral machine-readable format that drives CI checks, catalog registrations, and audit exports from a single source of truth.
None of this is new technology. The enforcement gap is not a tooling gap.
It is an ownership gap. When a contract is documented but not enforced, nobody's release fails when the contract is violated. The producer team does not see the breakage. The consumer team finds it three days or three weeks later, after the data has propagated through multiple layers. The cost of investigation is ten to fifty times higher than the cost of a CI failure would have been. We have seen this arithmetic play out at organizations ranging from 200-engineer startups to 30,000-person financial institutions. Scale changes the dollar magnitude; it does not change the pattern.
The contrarian position we take with every new engagement: a data contract program that does not make producer builds fail on violations is not a contract program. It is a documentation program with aspirations.
The four enforcement layers
Enforcement is not a single gate. It is a layered system where each layer catches different classes of violations at different points in the data lifecycle. Missing any one layer leaves meaningful failure modes uncovered.
Schema validation at the producer boundary. This is the highest-value layer and the one most often missing. At the point a producer writes data, whether to a Kafka topic, an S3 landing zone, or a lakehouse table, the schema is checked against the registered contract. Writes that violate the contract fail immediately. Confluent Schema Registry with compatibility mode set to BACKWARD_COMPATIBLE is the reference implementation for streaming producers. For batch pipelines, the equivalent is a schema assertion step wired into the ingestion job before any downstream processing starts.
The effect is forcing. A producer gets a build failure on the write, not a data team gets an alert three hours later. In our experience, producer teams that have previously ignored contract documentation start treating contracts as first-class requirements within one sprint of seeing their deploys fail.
Contract diffing in continuous integration. Before a producer's code change merges, a CI job compares the proposed output schema against the registered contract. Breaking changes fail the pull request. This is structurally the same discipline platform engineering teams apply to internal APIs: a breaking change to a REST endpoint fails the build until the version is bumped and consumers are notified. For SQL producers using dbt, model contracts enforce this natively. For non-dbt pipelines, a standalone contract-diff job using ODCS-formatted schema files provides the same guarantee.
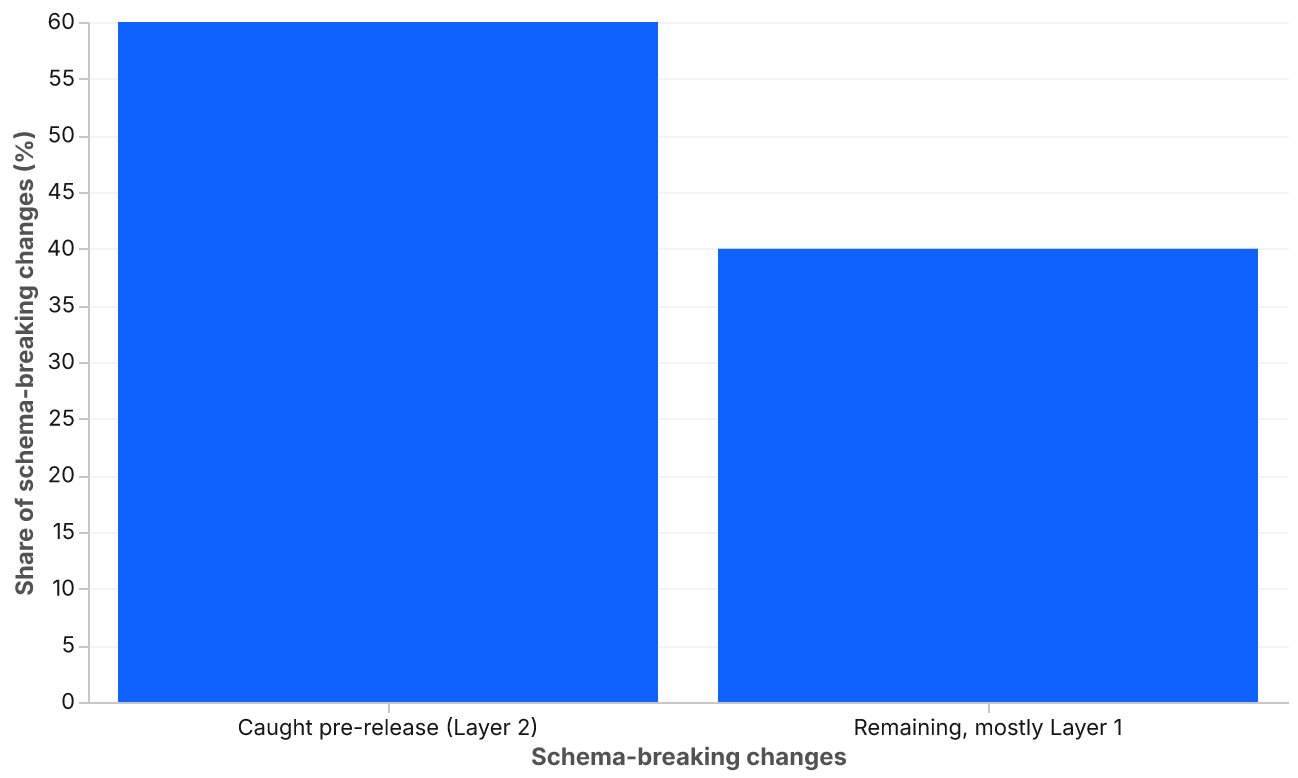
We estimate this layer catches roughly 60% of schema-breaking changes before they reach any shared environment, based on violation telemetry from the platforms we operate. Layer 1 catches most of the remaining 40%.
Runtime quality gates. Schema correctness is necessary but not sufficient. A column present with the correct type can still carry semantically invalid values: null where non-null was promised, negative revenue figures, referential integrity violations that pass schema validation but break downstream joins. Runtime quality gates check these constraints on actual data in flight.
The correct action when a runtime gate fires depends on the data's criticality. For a finance reconciliation feed, reject the batch and alert immediately. For a product telemetry stream, quarantine the bad records and continue processing clean ones. Define this policy per contract, not per tool, and document it in the contract's SLA section. When the policy is buried in framework configuration, it gets changed quietly during incidents and the contract no longer reflects reality.
Consumer-driven contract tests. The first three layers enforce what the producer promises. This fourth layer enforces what the consumer actually uses. A consumer registers the fields, types, and freshness expectations it depends on, and a test job verifies that the producer's output satisfies those dependencies on every release of either side.
This is the PACT-style contract testing pattern applied to data pipelines. It is well-established for microservices and underused in data. The discipline it creates is valuable: when a consumer depends on a field the registered contract does not guarantee, the contract is incomplete rather than the consumer's test being wrong. That distinction changes the accountability conversation significantly.
The producer-side ownership rule
The most common enforcement failure mode we see is building all four layers on the consumer side. Consumers write data quality checks against data they receive. Those checks fire after bad data has already landed and propagated. The producer learns nothing automatically. Fixing the problem requires cross-team coordination that rarely happens faster than two weeks.
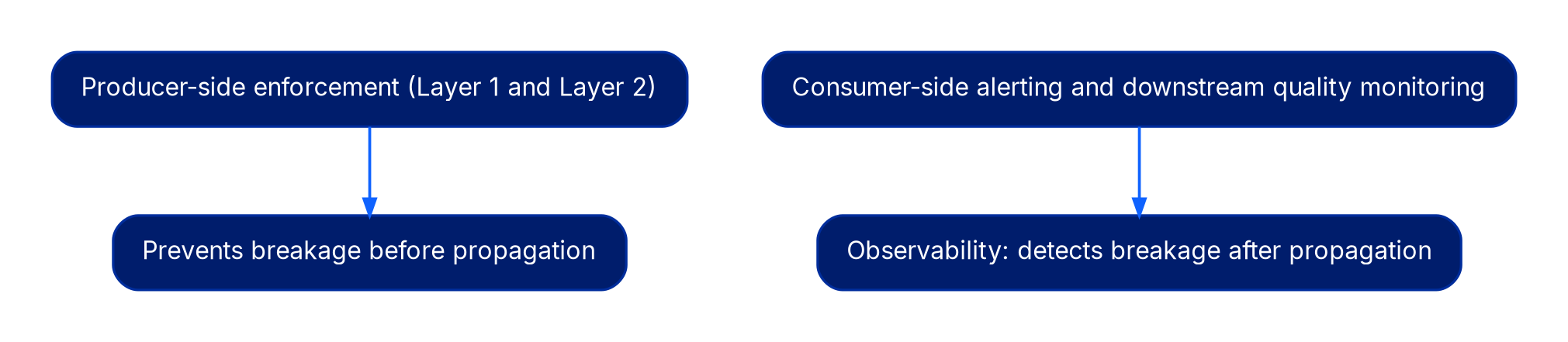
The counter-take we hold: enforcement belongs to the producer and must fire on the producer's release cycle. Layer 1 and Layer 2 are producer-side by design. If your enforcement strategy consists primarily of consumer-side alerting and downstream quality monitoring, you have an observability program. Observability detects breakage after propagation. Enforcement prevents it.
The cost difference is concrete. A data incident caught at the producer boundary during a CI run costs roughly one engineer and one to two hours of remediation. The same incident surfaced by a finance analyst three weeks later typically costs several weeks of investigation, a post-mortem, and an auditor conversation if the affected data feeds a regulated process. At organizations where we have both measurement points, producer-side enforcement has reduced data incident resolution time by 70% or more within the first two quarters of rollout.
Most engineering leaders accept this logic intellectually and then build consumer-side enforcement anyway, because producer teams resist owning contracts they did not write. The real ownership problem is not technical. Until producer teams are measured on data contract stability as a key result alongside feature velocity, contracts will lose to feature work. We have seen this dynamic at every organizational size. The solution is an explicit quarterly objective for producer teams, not better tooling.
What the tooling landscape actually provides
No tool enforces contracts without an ownership model to back it. Several organizations we have worked with deployed Great Expectations or Soda across 200 or more tables, generated thousands of quality alerts per week, and watched the program collapse under the noise within six months. The tool surfaced violations correctly. Nobody had a mandate to fix them, because the producers who created the violations had no accountability mechanism.
Once ownership is established, tool selection follows the layer structure:
For streaming producers, Confluent Schema Registry with broker-side schema enforcement is the default choice. The NIST AI Risk Management Framework requires documented data governance including provenance and quality criteria for organizations building AI systems; Schema Registry's audit log and schema evolution history satisfy that requirement without additional instrumentation.
For batch SQL pipelines built on dbt, model contracts are the natural fit. They live in the same repository as the transformation code, get reviewed in the same pull request, and add no additional tooling overhead.
For cross-team or multi-platform scenarios where a single producer feeds consumers across different systems, the Open Data Contract Standard gives teams a format that can drive CI checks, catalog registrations, and audit exports simultaneously.
Great Expectations and Soda belong at Layer 3, runtime quality gates, not as the primary enforcement mechanism. They excel at expressing complex semantic predicates that schema alone cannot capture, such as statistical distribution bounds or referential integrity across tables.
The most common sequencing mistake is buying a data observability platform before defining a single contract. The observability tool then surfaces thousands of anomalies against schemas nobody has agreed on, and the program drowns before it starts. Define five contracts in a source-controlled repository with CI checks first. Add observability tooling once you know what you are measuring.
The regulatory dimension
Enforcement is no longer purely an engineering concern for organizations operating in regulated industries. The EU AI Act, which entered force in August 2024 with high-risk system obligations phasing through 2026, requires documented data governance for training and evaluation datasets. An organization building AI systems on a data platform without Layer 2 or Layer 3 enforcement will need to produce manual lineage and quality evidence for every audit cycle.
BCBS 239, the Basel Committee's principles for effective risk data aggregation and risk reporting, has been formally in effect for large banks since 2016. Most institutions remain materially non-compliant on the data lineage and quality dimensions more than a decade later. Contract enforcement at Layer 1 and Layer 2 generates the violation history and lineage records compliance teams need without requiring quarterly archaeology projects against warehouse metadata.
The practical implication for platform leaders: framing enforcement as a regulatory risk reduction investment, rather than a developer experience investment, changes the budget conversation. We have seen organizations unlock platform budgets that were previously unavailable when the ask was quantified against audit exposure and potential regulatory penalty rather than against engineering productivity metrics alone.
Where to begin if you have not started
Resist the urge to enforce contracts across all tables simultaneously. Five tables enforced with discipline will teach your organization more than fifty enforced carelessly.
- Identify the five tables with the highest downstream consumer count or the most visible incident history in the past 12 months. These give enforcement the most organizational visibility and create the strongest ROI narrative for the next phase.
- Register explicit schema contracts for those five tables in a source-controlled repository. Assign a named producer team as owner for each contract. Specify compatibility mode and the deprecation window for breaking changes.
- Wire Layer 1 enforcement to the producer ingestion job so writes that violate the contract fail hard. Test the failure path deliberately before deploying to production.
- Add a contract-diff CI step to each producer's pipeline. Breaking schema changes must fail the pull request. Define the major-version bump and consumer notification process in the contract file before the first breaking change arrives.
- Define the runtime quality gate policy for each table: reject, quarantine, or alert, with the SLA documented in the contract. Instrument violation rates per producer per week from day one.
- Expand to the next ten tables only after the first five have run cleanly for 90 days. That window covers at least one quarterly release cycle and one infrastructure change event, both of which will test your enforcement under realistic production conditions.
- Revisit ownership incentives after the first 90 days. If producer teams are filing exceptions to bypass enforcement rather than fixing violations, the problem is not the tooling. An explicit engineering objective for data contract stability, owned at the VP level, is the intervention that works.
The firms pulling ahead on analytics reliability are not operating more sophisticated infrastructure. They are the ones whose producers know what they owe their consumers, and whose enforcement systems make it impossible to forget.
Continue reading
The Data Contract Problem: Why Your Lakehouse Keeps Breaking
Lakehouses do not break because of bad tooling. They break because nobody owns the schemas at the seam between producers and consumers.Lakehouse archi…
Strangler-Fig Modernization for Legacy Java and .NET Estates
Big-bang rewrites still fail at the same rate they did a decade ago. A practical strangler-fig sequence for Java and .NET estates that have to keep ru…
Strangler-Fig Migration from .NET to Java: A Practitioner's Sequencing Guide
The .NET-to-Java migration conversation surfaces more often than vendor briefings suggest. Java platform consolidation, Windows licensing pressure, an…