Strangler-Fig Modernization for Legacy Java and .NET Estates
Big-bang rewrites still fail at the same rate they did a decade ago. A practical strangler-fig sequence for Java and .NET estates that have to keep running.
The Standish Group's CHAOS reports have been telling us the same thing since 1995: large rewrites fail, often catastrophically, and the failure rate has barely moved despite three decades of methodology innovation. Standish's data on large projects (those over $10M) shows roughly 6% finish on time, on budget, and with the originally scoped functionality, while more than half are challenged and close to 40% are outright cancelled. The strangler-fig pattern, named by Martin Fowler in 2004 after the Australian rainforest vine, remains the most reliable answer, but its execution in Java and .NET estates has specific traps worth naming.
What the pattern actually requires
Strangler-fig is often described as "incrementally replace the legacy system." That description is true but unhelpful, because it omits the three constraints that determine whether the pattern succeeds: a routing layer that can split traffic at the seam between old and new, an event or data integration mechanism that keeps both sides consistent during the transition, and an organizational commitment to retire the legacy code paths rather than leave them as a permanent fallback.
Engagements that ignore the third constraint end up running the legacy and modern systems in parallel for years, paying double the operational cost and earning none of the agility benefits. We've seen organizations carry a "temporary" parallel run for 36 months or longer, at which point the parallel state becomes the architecture. The retirement commitment must be backed by an explicit decommissioning budget line and a named executive sponsor who will defend the deletion of running code against the inevitable late-stage objections.
A counter-take worth airing: the orthodox advice that you should always start with the strangler-fig pattern is wrong for small systems. If the legacy estate is under roughly 100K lines of code, has a single data store, and a team that fully understands it, a disciplined rewrite over one or two quarters is often cheaper and faster than the routing, dual-write, and observability scaffolding a strangler approach demands. The pattern earns its overhead at scale; below that threshold, it imposes ceremony without payoff. Practitioners who reflexively prescribe strangler-fig for every modernization are pattern-matching, not engineering.
Java estate sequencing
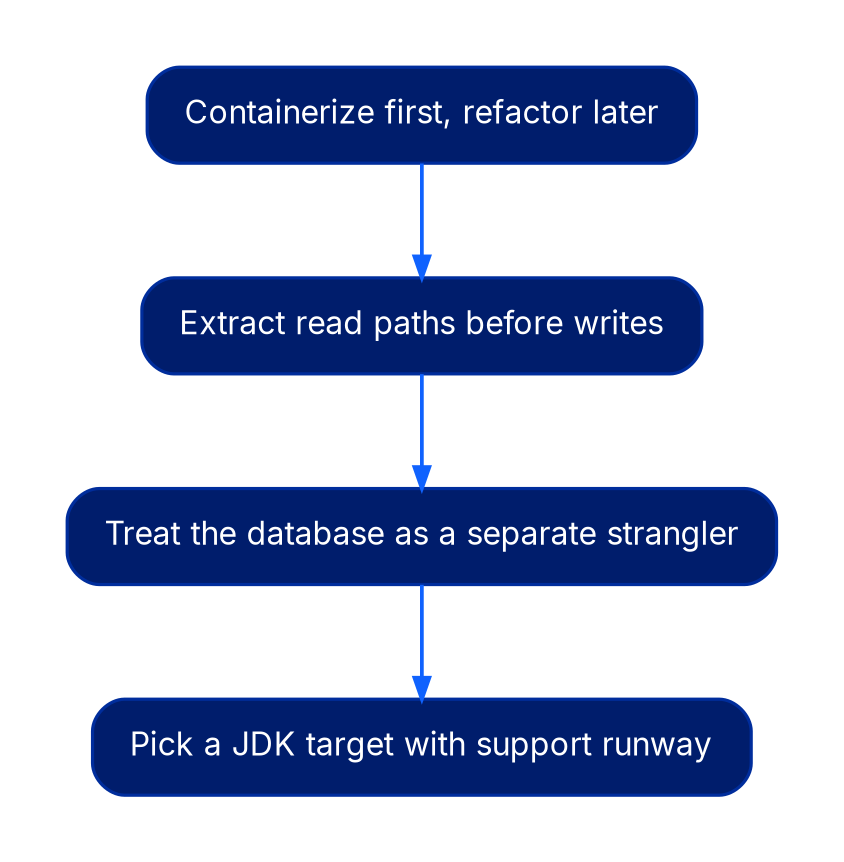
For long-lived Java estates, typically Spring 3.x or 4.x monoliths on WebLogic, WebSphere, or unsupported Tomcat versions, the productive sequence is usually:
- Containerize first, refactor later. Even an unmodified WAR moved into a container on Kubernetes gives you the deployment substrate the strangler pattern needs. Skip the urge to upgrade Java and Spring versions in the same step. Spring Framework 5.x reached end of OSS support on December 31, 2024, which means many estates are now running unsupported framework versions; resist the temptation to fix that and the deployment model in the same change window.
- Extract read paths before writes. Read-only services tolerate eventual consistency between old and new far better than writes. They also let you build your routing and observability muscle on lower-risk traffic. We typically run shadow traffic at 5% to 10% for two to four weeks before promoting a read path to primary, with diff logging on response payloads.
- Treat the database as a separate strangler. The shared schema is usually the hardest constraint. Plan for parallel write, dual read with shadow comparison, then cutover, not a single migration script. Tools like Debezium for change data capture, paired with a transactional outbox in the legacy application, give you the consistency guarantees that naive ETL approaches lack.
- Pick a JDK target with support runway. JDK 21 LTS receives Oracle Premier Support through September 2028, with extended support through 2031. Migrating from Java 8 directly to 21 is generally less work than the intermediate steps, because the breaking changes between 8 and 11 dominate the effort budget regardless of where you stop.
WebLogic and WebSphere migrations carry an extra constraint worth flagging: applications often depend on container-managed transactions, JNDI lookups, and proprietary clustering primitives that have no clean equivalent on Tomcat or Spring Boot. Inventory these before scoping. We've seen estimates double when a JCA resource adapter or a stateful EJB with passivation surfaces in week six of a migration.
.NET estate sequencing
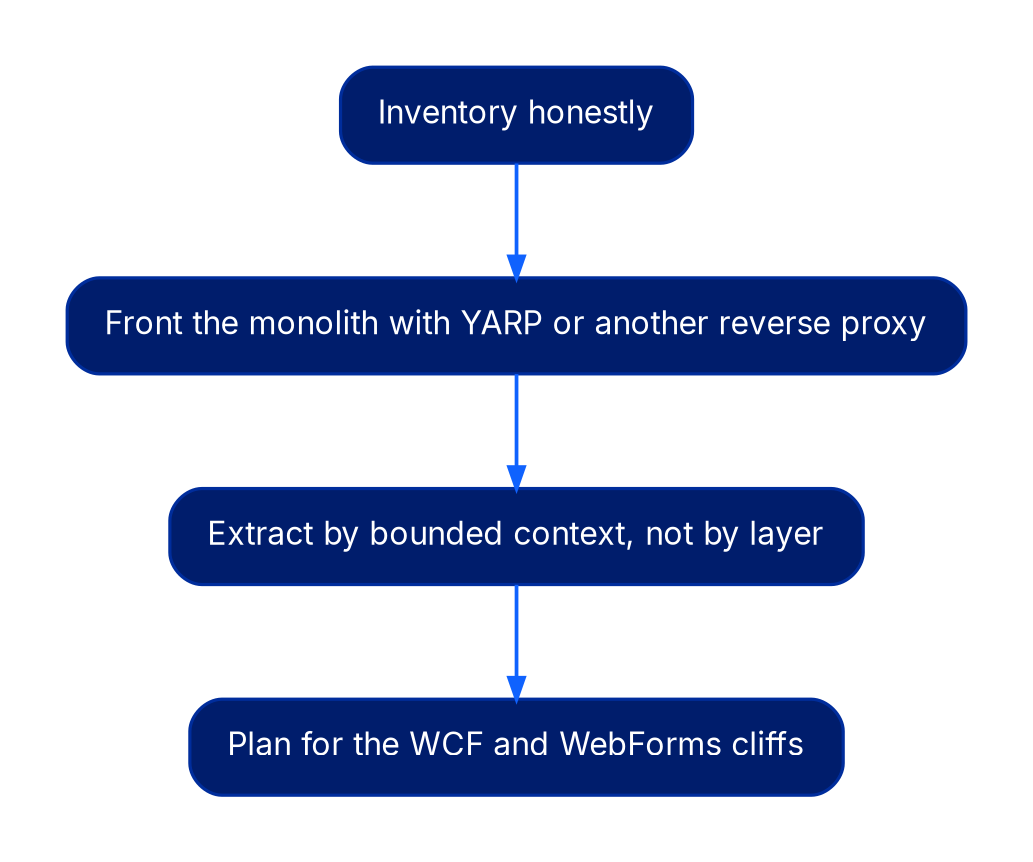
.NET Framework estates have a different shape. The path forward is usually .NET 8 or later, which means a real port rather than a recompile in many cases. Microsoft's official position, documented in their .NET Framework support policy, is that .NET Framework 4.8 remains supported as a Windows component, but no new feature work will land there. The sequence we use:
- Inventory honestly. The biggest .NET migration risk is dependencies on legacy COM components, third-party controls, or in-house libraries built on .NET Framework primitives that have no .NET Core equivalent. Find these before you scope the timeline, not during cutover. Microsoft's
try-converttool and the .NET Upgrade Assistant give you a first-pass compatibility report; expect roughly 70% to 85% of code to port cleanly and the remainder to require manual intervention. - Front the monolith with YARP or another reverse proxy. Microsoft's YARP gives you the same routing seam that an API gateway provides, without forcing a service mesh decision in the same quarter. YARP runs in-process on ASP.NET Core and is what Microsoft itself uses for several of its production gateways.
- Extract by bounded context, not by layer. The instinct to "extract the data access layer" or "extract the API layer" is almost always wrong. Strangler-fig works at the bounded-context level, a slice of business capability with its own data, not at architectural-layer level. A horizontal slice gives you a distributed monolith with worse latency and the same coupling.
- Plan for the WCF and WebForms cliffs. WCF server-side has no first-party port to .NET 8; the community CoreWCF project covers a substantial subset, but not the full WS-* stack. WebForms has no port at all. If your estate leans on either, the realistic path is rewriting those surfaces to gRPC or minimal APIs and to Blazor or a SPA respectively, not lifting them.
The execution risks that recur
Three patterns derail strangler-fig migrations more than any others.
The first is allowing the new system's tech stack to be chosen by enthusiasm rather than fit. The right answer is usually boring: the same major framework version your team uses elsewhere, the same data store family, the same observability pipeline. We've watched migrations stall because the team picked an event-sourced architecture for a CRUD application, or chose a polyglot persistence approach that required hiring for skills the organization did not have. Modernization is not the time to also adopt three new technologies.
The second is letting the legacy code freeze, which sounds prudent but starves the legacy of the maintenance investment it needs to remain stable during a multi-quarter migration. A frozen legacy accumulates security debt and operational fragility precisely when its uptime matters most. We recommend an explicit policy that the legacy continues to receive security patches, dependency upgrades, and bug fixes for any code path that has not yet been retired, with a separate small team accountable for that work.
The third is treating the migration as an engineering project rather than a product one. Without a product owner empowered to retire features, the new system inherits every accidental complexity of the old. We routinely find that 15% to 30% of legacy features have no active users, and another tranche have workflows that exist only because the legacy system imposed them. A migration without product authority to delete is a re-implementation, and re-implementations regress to the rewrite failure rate Standish has been tracking for thirty years.
A fourth risk, less universal but worth flagging in regulated industries: the routing and dual-write infrastructure itself becomes an audit surface. If you operate under SOX, PCI-DSS, or banking supervisory regimes, the proxy layer and the change-data-capture pipeline both fall in scope. Build the audit evidence model in the first sprint, not the last.
How long this takes
For a Java or .NET estate of 500K to 2M lines of code, a realistic strangler-fig migration runs 18 to 30 months from first extraction to final retirement of the legacy system, with measurable business value beginning in month 4 to 6. Anyone promising faster is selling a rewrite under a different label.
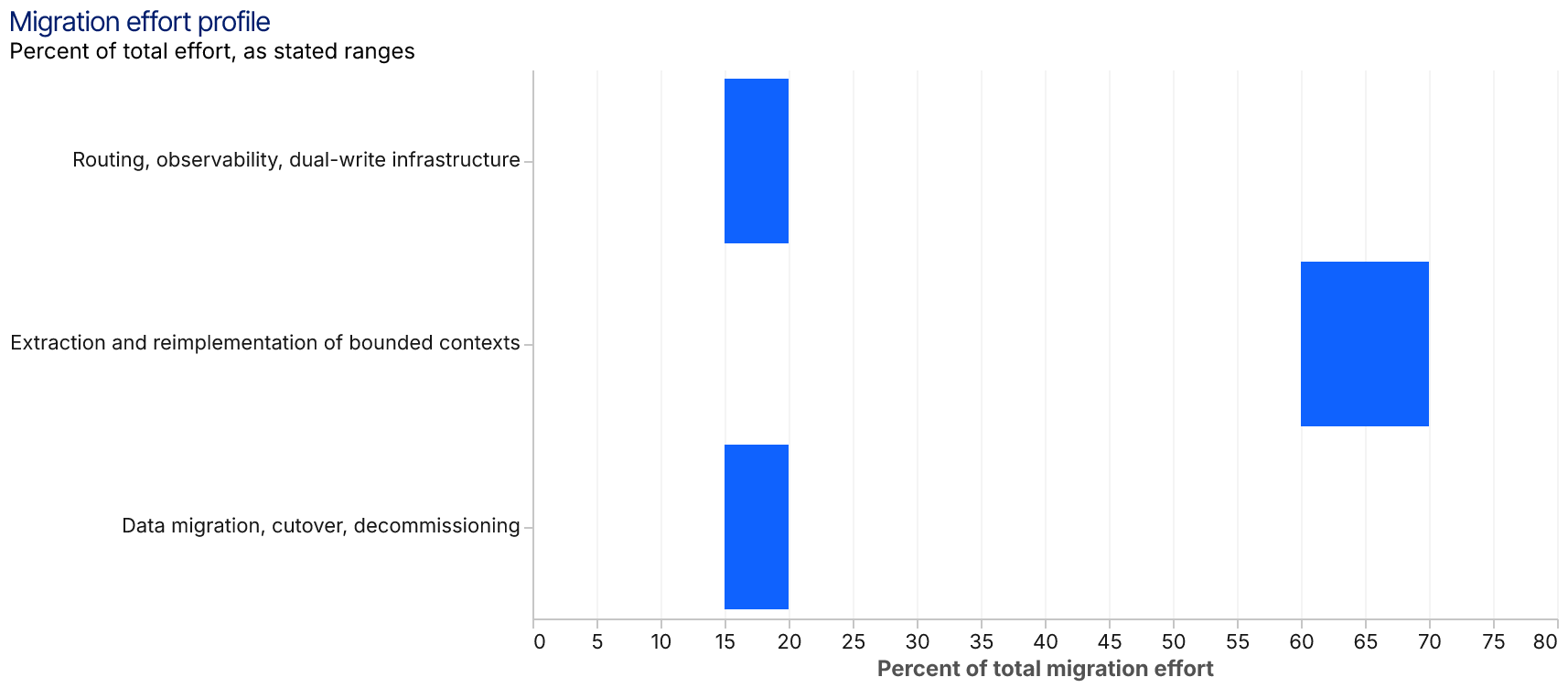
The cost profile is roughly: 15% to 20% of total effort on the routing, observability, and dual-write infrastructure that enables the pattern; 60% to 70% on the actual extraction and reimplementation of bounded contexts; and the remaining 15% to 20% on data migration, cutover, and decommissioning. Organizations that under-invest in the first bucket pay for it three times over in the second.
For estates above 2M lines, or where the database schema spans more than a dozen tightly coupled subject areas, expect 30 to 48 months and plan for at least one mid-course architectural correction. The teams that complete these migrations treat the corrections as a feature of the approach, not a failure of planning. Estates above 5M lines often require splitting the program into independently sequenced sub-migrations with their own product owners; at that scale, a single program governance model collapses under its own coordination cost.
What success actually looks like
The migrations that finish share a few characteristics. The routing seam is owned by a small platform team with a clear interface contract, not negotiated per-extraction. Observability is uniform across legacy and new from day one, including distributed tracing that crosses the proxy boundary, so that performance regressions in the new system are visible before customers report them. The decommissioning of legacy code is celebrated and tracked publicly, often as the primary program metric, because it is the only metric that cannot be gamed by partial extractions.
The migrations that fail tend to share a different signature. They report progress in terms of services extracted rather than legacy code retired. They run the legacy and new systems in parallel for so long that the parallel run becomes the architecture. They accumulate a backlog of "we'll clean that up later" exceptions in the routing layer until the routing rules themselves are the most complex piece of code in the system.
The bottom line
Strangler-fig is not glamorous and it is not fast, but it is the most reliable way to modernize a system you cannot turn off. The pattern works; the execution discipline is what separates the organizations that finish from the ones that abandon the project two years in. The tooling has improved markedly in the last five years, particularly on the .NET side with YARP and on the Java side with Debezium and the maturation of Kubernetes operators for stateful workloads, but the human and organizational constraints have not changed. Get the routing seam, the data integration, and the retirement commitment right, and the rest is engineering. Get any of the three wrong, and no amount of engineering will save the program.