Building an AI Governance Framework That Ships to Production
Governance documents don't enforce themselves. How to close the gap between policy intent and the production control layer that actually enforces it.
Almost every enterprise running AI in production has documentation describing how models are evaluated, approved, and monitored. Far fewer have the production controls needed to enforce those policies when a model misbehaves on a Friday night. The NIST AI Risk Management Framework provides detailed guidance on governance operationalization precisely because that translation from policy to executable control is where most programs fail. We see the same gap in nearly every engagement we take on: the policy exists, but nothing in the runtime enforces it.
The consequence is predictable. A model drifts. Or a vendor quietly retrains an endpoint. Or an edge case in a prompt template produces output the policy explicitly prohibits. The incident review asks why governance did not catch it. The answer is that governance was never wired to the system. A set of documents is not a control.
Why most governance frameworks stop at the policy layer
The word "framework" in AI governance is ambiguous enough to cover a wide range of artifacts. In practice, most frameworks are document sets: a risk taxonomy, an approval checklist, a list of prohibited use cases, a handful of monitoring requirements. Each piece is coherent on its own. Together they describe an ideal process that does not survive contact with how engineers actually ship and operate machine learning systems.
The contrast with security governance is instructive. Mature security programs treat the security policy as intent and the security controls as governance. Firewall rules, automated static analysis in the CI pipeline, anomaly detection alerts wired to an on-call rotation: these are what governance looks like in production. An AI governance program that produces only policy documents is the equivalent of a security program that published a password policy but never deployed an identity provider. The intent is present. The enforcement is not.
The counter-take we offer to clients: the primary deliverable of an AI governance initiative should not be a policy document. It should be a control library, a CI/CD pipeline stage, and a production dashboard. If the deliverable is not deployable code or infrastructure configuration, the program has built the prerequisites for governance, not governance itself.
The five layers of a production governance framework
A framework built to function in production has five concrete layers, each with a testable output and a clear owner.
Risk classification. An automated function that takes a use-case description and returns a risk tier, consistently, in under five seconds. Not a committee vote on each case. We recommend scoring four dimensions: regulatory exposure, customer-impact scope, output autonomy (does the model decide or assist?), and data sensitivity class. The function produces a tier from one to four. That tier drives every downstream control requirement. It runs in CI before any new use case or model deploys. Teams slow down at intake not because the approval workflow is slow but because classification is ambiguous and contested. Make it mechanical and the delays largely disappear.
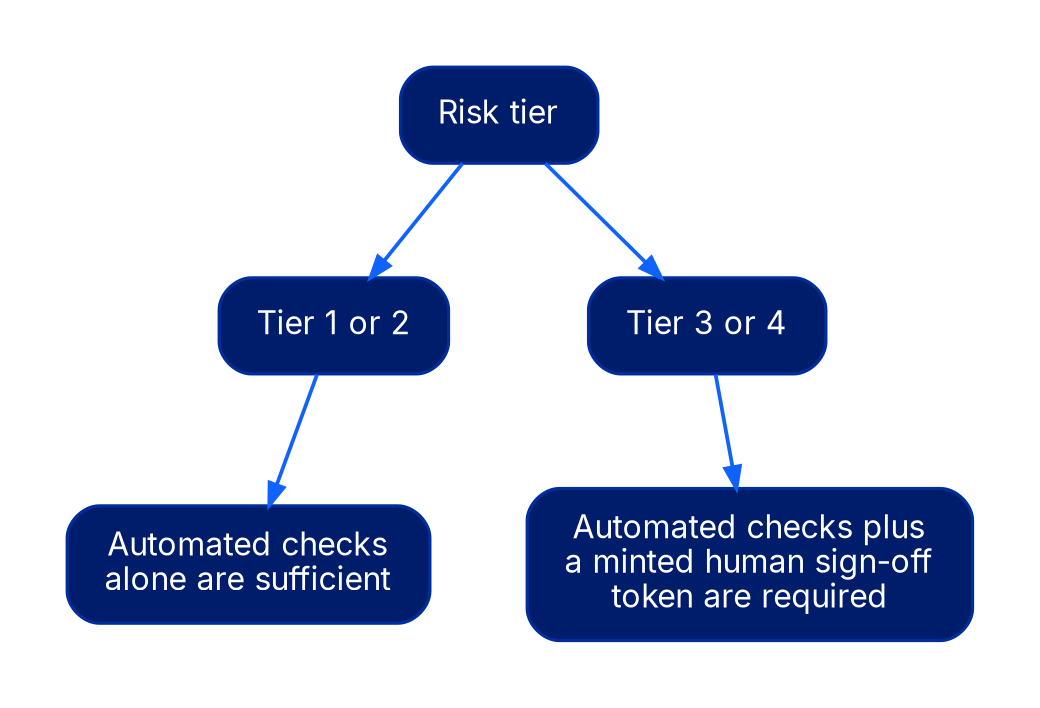
Approval gates. Tier-dependent pipeline checks that must pass before a use case reaches production. For tier 1 and 2 cases, automated checks are sufficient: evaluation coverage above a defined threshold, a versioned prompt and tool configuration in the registry, latency and cost SLO definitions, and a named on-call owner. For tier 3 and 4 cases, automated checks are prerequisites but not sufficient; a human sign-off token must be minted by the appropriate authority and embedded in the deployment artifact. Either way, the output is a signed attestation, not a completed form in a ticketing system.
Runtime controls. Input validation, output filtering, PII detection, and abuse flagging that execute on every inference call. These belong in the middleware layer of the serving stack, not on a feature backlog for later. Each control must be configurable per use case, so a customer-facing application gets stricter filtering than an internal analytics tool, but the configuration lives in the governance registry rather than in application code. When configuration lives in application code, the first exception request removes it permanently, and no one remembers it was there.
Observability. Governance metrics routed into the same observability platform as production reliability metrics. The signals that matter most are drift on input distribution, accuracy proxy against a reference evaluation set, fallback invocation rate, and policy violation rate. We add one signal most programs omit: approval-to-deployment lag. If a use case spent 45 days waiting for approval, that lag is a leading indicator of shadow AI activity in the next quarter.
Evidence collection. Automated generation of audit artifacts at each layer. Every approval gate produces a timestamped, signed record. Every monitoring alert and every rollback produces a corresponding change record. The technical documentation requirements in Annex IV of the EU AI Act for high-risk systems are specific about provenance of training data, evaluation results, and change history. Reconstructing that evidence after an audit request is expensive and often incomplete. Generating it automatically in the ordinary course of operations is a roughly two-sprint engineering project if the pipeline is wired correctly.
Engineering the governance feedback loop
Frameworks decay. The policy written in Q1 describes the risk landscape as of Q1. By Q4, models have been updated, use cases have expanded, new vendors have been onboarded, and the regulatory environment has shifted. Static documents have no mechanism to detect this divergence. Production systems do.
The feedback loop runs on two time horizons. The operational loop runs continuously: monitoring signals feed a risk dashboard, thresholds trigger alerts, alerts route to an on-call rotation whose runbooks pre-authorize the acceptable responses. An on-call engineer responding to a drift alert at 11 PM does not need to convene a committee. The runbook specifies whether to throttle, route to human review, or page the model owner. That pre-authorized decision logic is governance; a SharePoint policy document is not.
The strategic loop runs quarterly: all production AI systems reviewed against the current risk taxonomy, approval-to-deployment lag audited for process bottlenecks, evaluation benchmarks refreshed for distribution shift, vendor lifecycle notices reconciled against registered use cases. This is what keeps the operational loop accurate. Without it, the controls enforce a policy that has gradually stopped describing reality.
The original Model Cards for Model Reporting paper by Mitchell et al. established that model cards should be living documents tied to evaluation results, not frozen artifacts. Most enterprise implementations freeze them at approval and never refresh them. A framework that treats any governance artifact as permanent will eventually govern a system it no longer recognizes.
Three engineering mistakes that produce governance gaps
Three patterns account for most of the production governance failures we investigate after incidents.
The first is instrumenting the model instead of the system. A single model inside a chain of retrievers, tools, re-rankers, and post-processors is not the unit of governance risk. The system is. We have seen incident reviews where the model performed exactly within approval scope, but a retrieval component injected content that violated output policies. The governance controls were attached to the wrong boundary. Scope the controls to the full inference pipeline, not the model call in isolation.
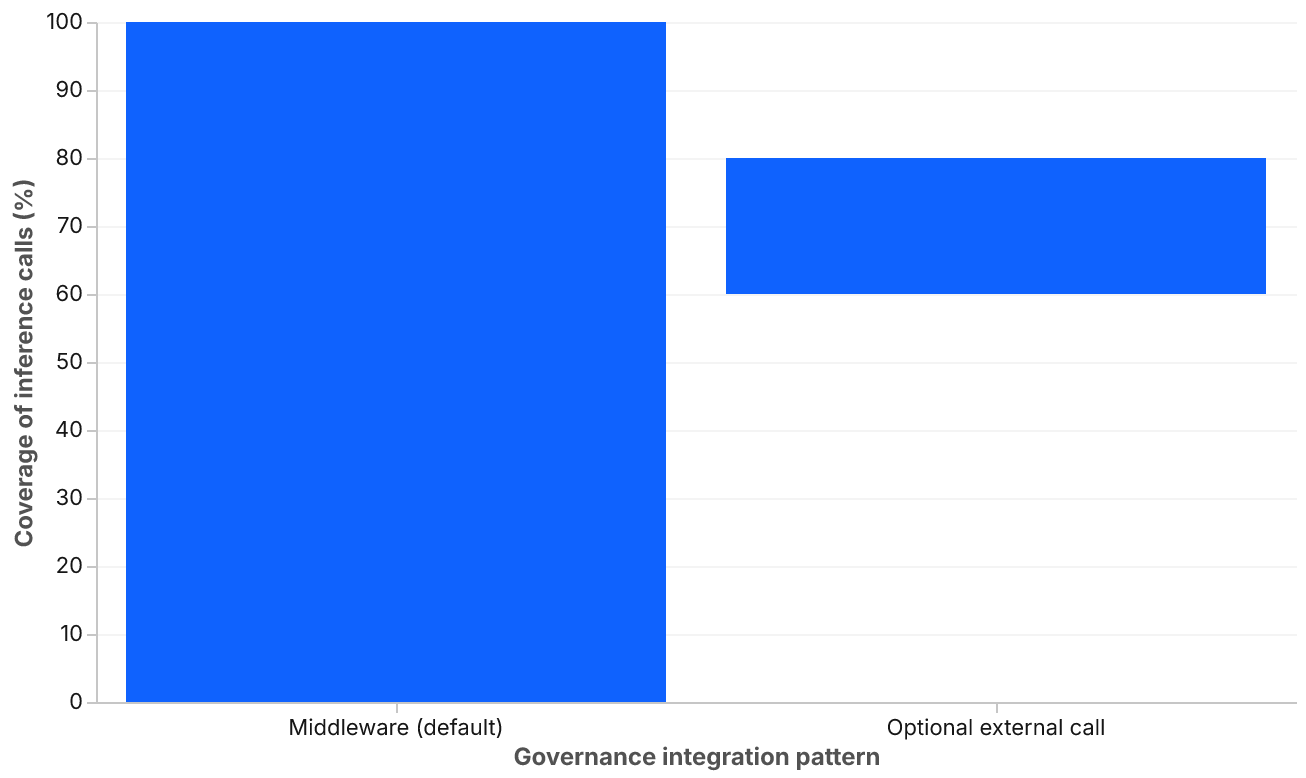
The second is building governance as a separate service rather than middleware. A standalone "AI governance service" that applications must call explicitly develops coverage gaps within a few months, because teams take exceptions, prioritize velocity, or forget. Governance as middleware in the serving framework runs on every call by default, with opt-outs requiring an explicit override that is logged. Coverage as middleware approaches 100%. Coverage as an optional external call typically lands between 60% and 80% in our experience, with the uncovered fraction concentrated in the highest-risk integrations.
The third is treating model versioning as equivalent to use-case governance. Registering model v2.3 as approved says nothing about whether the 17 applications depending on it are still operating within their original approval scope. Governance requires a use-case inventory with explicit dependency mapping to models, prompts, and data sources. Organizations that maintain this mapping resolve incidents roughly 40% faster than those maintaining only a model registry, because the blast radius of any model change is immediately visible before anyone starts investigation.
Putting it into operation
- Run a current-state audit: map every production AI use case to a risk tier. Flag cases with no explicit approval record as deficient. These are your first rollback candidates if an incident occurs before the program reaches full coverage.
- Instrument two governance signals per use case within 30 days: drift on input distribution and fallback invocation rate. These two signals surface approximately 70% of meaningful degradation in a typical production portfolio without requiring a bespoke observability build.
- Assign on-call ownership to every production AI system before the next deployment cycle. No production system should exist without a named human who can authorize a rollback within 15 minutes.
- Embed the approval gate in CI for all new use cases. Do this before expanding the portfolio. Adding use cases without a functioning gate recreates the governance debt the program is intended to retire.
- Run a governance tabletop exercise within 60 days. The specific scenario matters less than the practice. Walk from detection through escalation to rollback to customer communication. The gaps it surfaces are worth more than months of additional policy drafting.
- Establish a quarterly review cycle: update the risk taxonomy against current regulatory guidance, refresh evaluation benchmarks, reconcile vendor lifecycle notices, and publish a one-page summary of governance metrics for leadership review.
The bottom line
AI governance that functions in production looks more like site reliability engineering than compliance documentation: runbooks, dashboards, on-call rotations, and post-incident reviews. The policy document should be an output of that operational system, not an input to it. Organizations that start with the enforcement infrastructure and let the documentation follow from its artifacts end up with governance that is both auditable and enforceable. Organizations that start with the document and plan to add enforcement later rarely get to "later." Build the control layer first.
Continue reading
AI Red Teaming in Regulated Industries: Why Most Programs Fail the Exam
Most large financial institutions and healthcare systems have run at least one AI red team exercise. Few have run one their compliance function could …
Securing the LLM Supply Chain: Threat Models for AI-Powered Apps
Most enterprise application security programs were designed for deterministic systems. LLM-powered applications break enough of those assumptions that…
From RPA to Agentic Automation: When to Graduate, When to Stay
Every major RPA vendor, UiPath, Automation Anywhere, Blue Prism, is repositioning around agentic AI. Their message: deterministic RPA is yesterday; LL…