AI Red Teaming in Regulated Industries: Why Most Programs Fail the Exam
Most large financial institutions and healthcare systems have run at least one AI red team exercise. Few have run one their compliance function could point to during a regulatory exam. That gap is the core problem, and it is widening as AI deployments multiply faster than test programs mature.
OCC Bulletin 2011-12 treats adversarial testing of model behavior as a component of sound model validation, and the FCA has issued comparable expectations for machine learning used in consumer-facing credit decisions. The EU AI Act mandates adversarial robustness and bias testing for enumerated high-risk AI categories, including credit scoring and biometric identification, with enforcement beginning August 2026. Regulators are asking questions that a standard red team exercise, scoped around jailbreaks and system-prompt extraction, was never designed to answer.
We have worked through this problem with banks, insurers, and health systems operating under active regulatory oversight. The core issue is that regulated-industry red teaming must prove something different from what security research red teaming proves. Security-focused adversarial AI research asks: can an attacker make this model do something unexpected? A regulator asks: can this model generate a consumer harm, a fair-lending violation, or a privacy breach under conditions your test environment did not anticipate? Different questions. Different test designs. Programs that conflate the two tend to produce reports that impress CISOs and confuse examiners.
Why standard red team scopes miss the regulatory target
The dominant red team methodology for large language models draws from security research: probe for prompt injection, jailbreaks, data exfiltration, and output manipulation. These are real risks and worth testing. But the threat models that govern financial services and healthcare weight failure modes differently.
The NIST AI Risk Management Framework assigns adversarial testing responsibilities explicitly in its Measure function, requiring ongoing red-teaming, bias evaluation, and results that feed back into the risk posture record. OCC 2011-12 requires that validation be independent from model development and that testing cover out-of-sample data with documented limitations. The EU AI Act Article 9 mandates a risk management system with iterative testing throughout the AI lifecycle. None of these frameworks are primarily asking whether an adversary can extract the system prompt. All three are asking whether the model fails in ways that harm consumers or generate regulatory exposure.
The scope mismatch is structural. A security researcher exercise finds novel attack vectors and demonstrates impact on confidentiality and availability. A regulatory-aligned adversarial test finds cases where the model produces wrong or biased outputs for real users in the normal course of business. Both are worth running. Neither is a substitute for the other. Most regulated-industry programs treat them as if they were, and the examination record shows it.
The counter-take on "all red teaming is the same"
Conventional advice says adversarial AI testing is a single discipline and any competent red team can cover both security and regulatory objectives. We disagree, and the disagreement is grounded in what we observe in practice rather than in theory.
A security-oriented red team has the expertise to find injection vectors and exfiltration paths. It does not carry a working model of adverse action notification obligations, FCRA Section 615 accuracy requirements, or HIPAA minimum-necessary standards. A compliance-oriented model validation team carries those frameworks but rarely has the technical depth to probe instruction-following failures, multi-turn context manipulation, or adversarial distribution shift at the output layer.
Effective regulated-industry red teaming requires both skill sets operating from the same test plan, measured against the same success criteria. Most programs have one or the other. Firms run security red teams in Q1 and model validation reviews in Q3. Neither report references the other. The security report describes a jailbreak the compliance team cannot evaluate for regulatory impact. The validation report describes accuracy degradation the security team never tested. A regulator reading both during an examination sees two partial pictures of a system that was never tested as a whole.
What a regulated-industry exercise actually tests
We structure these engagements around three test domains that correspond to distinct regulatory obligations.
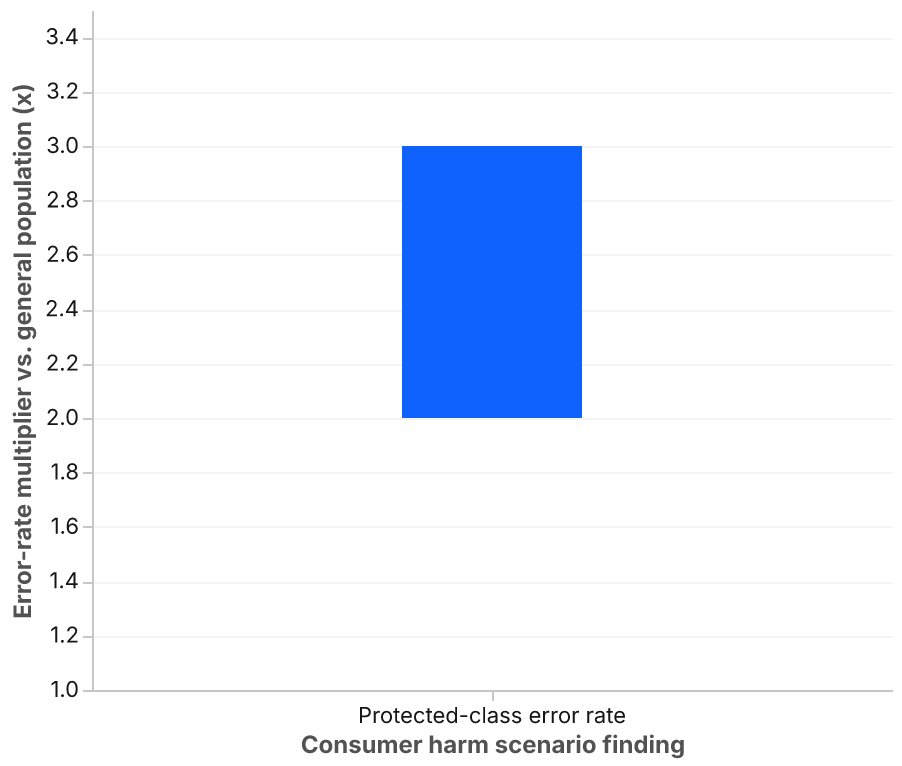
Consumer harm scenarios. The test team constructs inputs designed to produce outputs that would harm real users: incorrect benefit denials, biased credit recommendations, clinical suggestions that contradict evidence-based guidelines. The criterion is not whether the input looks adversarial. It is whether the output, if acted on, would harm a real person. Some of the highest-impact cases in our practice involve ordinary-looking inputs that produce wrong answers for a protected demographic class at a rate 2x to 3x higher than for the general population. Standard security test methodologies do not surface this class of failure.
Regulatory documentation stress tests. Regulators expect that an institution can explain any model decision in a way that satisfies adverse action, model risk, or data protection obligations. The procedural test is this: sample 50 outputs from the red team exercise and ask whether the institution could, within 24 hours, produce a defensible explanation for each that meets the applicable standard. For US credit decisions, that standard is the ECOA adverse action notice requirement. In our experience, fewer than 30% of AI deployments in regulated industries pass this test on first attempt. The failure is rarely about the model. It is about the absence of explanation infrastructure.
Adversarial distribution shift. Models trained before 2023 are operating on input distributions that have shifted materially, particularly in financial services where interest rate environments, fraud patterns, and customer behavior changed in a compressed window. Exercises using only synthetic adversarial inputs miss the largest source of silent model failure: inputs that are entirely normal by training-distribution standards but anomalous in the current operating environment. We build test sets from production data observed in the 90 days before the exercise, not from published academic benchmarks. This approach consistently surfaces more high-severity findings than synthetic inputs do, because production anomalies are specific to the institution's actual deployment context.
What regulators actually require
Three frameworks govern most regulated-industry AI programs in our practice, and their specific requirements are more actionable than most firms realize.
NIST AI RMF is technically voluntary, but both the OCC and the SEC have cited it in recent supervisory letters as a reasonable baseline for AI risk management practice. The Measure function is concrete: it requires identification of AI risks using established methods, measurement of those risks at scale, and systematic testing for bias and robustness. Firms treating the AI RMF as an aspirational checklist rather than an operating framework are consistently less prepared when examiners arrive.
OCC 2011-12 examination manuals have incorporated adversarial robustness into the scope of independent model validation with increasing frequency since 2022. The standard was always there; what changed is examiner focus. Banks that cannot demonstrate systematic adversarial testing are receiving findings. The pattern is consistent across our client base.
The EU AI Act brings the most explicit requirements. Article 9 mandates iterative testing throughout the AI lifecycle. Article 11 requires technical documentation with records of validation and adversarial evaluation. Post-market monitoring is mandatory and must feed back into the risk management system. For any entity deploying AI in a high-risk category, these are compliance requirements with an August 2026 enforcement date. That documentation work cannot be completed under deadline pressure; it must be produced alongside the testing program.
Building a program that holds under examination
The most common structural failure we see is treating red team exercises as events rather than as a continuous program. An annual penetration test is the standard framing. It produces a point-in-time report that starts aging the moment it is issued.
Regulated-industry requirements are not point-in-time. OCC and FCA both expect ongoing model monitoring and periodic independent validation. The EU AI Act requires a post-market monitoring system that feeds back into the risk management record. A red team program adequate for an examined institution looks like a standing function: a defined test cadence of at minimum quarterly for high-risk models, a closed-loop remediation workflow that ties findings to model validation records, and a test library that evolves as the model and its deployment context change.
Three elements distinguish programs that survive regulatory scrutiny from those that do not.

The first is scoring findings against regulatory harm categories rather than CVE-style severity classifications. A jailbreak that causes pirate-themed output is high severity by CVE convention. It is low regulatory severity unless the deployment context creates consumer exposure. Regulators read harm narratives, not severity scores. The test plan scoring should match what the examiner is going to read.
The second is linking every finding that touches model accuracy, bias, or consumer impact to a model documentation artifact. A red team finding that exists only in a security report is invisible to the model risk management process. That linkage makes the program auditable and prevents the same finding from surfacing again in the next examination cycle because it was addressed in a system the compliance team could not see.
The third is closing each exercise with a regulatory response drill. Present the three most impactful findings to a simulated regulatory audience and run a question-and-answer session. The findings that cause difficulty in the drill are the exact ones that will cause difficulty in an actual exam. This drill takes one afternoon and surfaces preparation gaps months before they become examination findings.
Where to start this quarter
- Audit your current red team methodology against the three test domains above: consumer harm scenarios, regulatory documentation stress tests, and adversarial distribution shift. Identify which domains are not currently covered and assign ownership before the quarter closes.
- Pull the last 90 days of production inference logs from your highest-risk AI deployment. Compare the current input distribution to the validation dataset. Flag inputs more than 2 standard deviations from the training mean for inclusion in the next test cycle.
- Map every AI red team finding from the past 12 months to a specific model documentation artifact. Any finding without a corresponding documentation update should be escalated to model risk management within 30 days.
- If you are subject to EU AI Act obligations for any high-risk AI system, begin an Article 9 and Article 11 gap assessment now. The August 2026 enforcement deadline is closer than planning horizons suggest once you account for documentation, testing, and internal review cycles.
- Require that the next red team engagement include at least one practitioner with model risk management or regulatory compliance experience alongside the security team. Technical depth alone is no longer sufficient for programs in examined institutions.