Building an Internal Developer Platform Your Engineers Will Use
Internal developer platforms are having a moment. Backstage adoption is up, "platform engineering" is the title du jour, and most large enterprises now have a team building one. Gartner projects that 80% of large software engineering organizations will have established platform engineering teams by 2026, up from roughly 45% in 2022. The trouble is that most of those platforms will be quietly bypassed within eighteen months, because they are designed as a project rather than as a product.
We've spent enough time inside platform programs to recognize the pattern early. The slide decks promise developer productivity, the architecture diagrams are crisp, the first six months feel productive, and then somewhere around the one-year mark the platform team realizes that adoption has plateaued at a fraction of the engineering organization. The remaining teams have read the docs, tried the paved road, and gone back to whatever they were doing before. The platform did not lose on technical merit. It lost on product judgment.
The two failure modes
Internal platforms fail in two predictable ways. The first is the _ignored portal_: a Backstage or homegrown UI sits unused while engineers continue to deploy via Terraform from their laptops, because the platform did not save them enough time to justify learning a new workflow. The second is the _mandated bottleneck_: usage is forced via policy, but the platform team cannot keep pace with feature requests, and the platform becomes the constraint that engineering velocity used to blame Jira for.
Both failures share a root cause: the platform was scoped as infrastructure, not as a product, and it shipped without the discovery and feedback loops a product would have. In our work with enterprise platform teams, we typically find that the original charter document mentions "developer experience" as a goal but contains zero artifacts you would expect from a product team: no personas, no user research notes, no journey maps, no measured baseline of the workflows the platform is meant to replace. The team starts building before it knows what it is competing against.

A third, less-discussed failure mode is worth naming: the _rebuilt cloud console_. This is the platform that wraps AWS or Azure primitives in a custom UI without meaningfully simplifying them, on the theory that engineers want a "single pane of glass." They do not. They want fewer panes of glass total, and a wrapper that exposes every underlying knob is just one more pane.
What "product mindset" actually means in practice
The phrase is overused. Concretely, it means three things for a platform team:
- You have customers, and they can choose not to use you. Even when usage is officially mandatory, engineers can route around platforms they dislike, via shadow tooling, escape-hatch exceptions, or simply slow adoption. A platform team that does not believe its users have alternatives builds for itself.
- You measure adoption and time-to-value, not features shipped. The right metric is not "number of services on the platform" but "median time from a new engineer's first commit to their first production deploy via the platform." That number is brutal but honest. The 2023 DORA State of DevOps Report found that elite-performing teams deploy on-demand multiple times per day with lead times under one hour, while low performers measure lead time in months. The gap is almost always developer experience, not technology choice.
- You ship a paved road, not a buffet. Platforms that try to support every framework, language, and deployment topology dilute their value. The most successful platforms we see commit to a small set of golden paths and make them dramatically better than the alternatives.
The product-mindset framing has its critics, and one objection deserves a serious answer. The objection is that platform engineering is not really product work because the customers are captive: they cannot churn to a competitor, and the platform team's funding does not depend on satisfying them. Treating engineers as customers, the argument goes, is a polite fiction that obscures the platform team's actual job, which is to enforce organizational standards.
We disagree, and the evidence is in the bypass rates. Engineers absolutely can churn. They churn to local Terraform, to per-team Kubernetes clusters, to the cloud console, to skunkworks platforms built inside product groups. They churn through exception requests, through "temporary" workarounds that calcify, and through hiring patterns that quietly favor teams that have been allowed to opt out. A platform that enforces standards without earning use ends up with neither standards nor use.
The capability stack that matters
An internal developer platform that earns its keep covers six capabilities, in roughly this order of priority:
- Self-service environment provisioning. A new service or environment in minutes, not days. The reference target we use is under 15 minutes from request to a working namespace with networking, identity, and a deploy target wired up.
- Standardized CI/CD with sane defaults. Engineers should not be authoring pipelines for common cases. A Go service, a Python service, and a Node service should each have a one-line opt-in to a tested pipeline.
- Observability defaults wired in. Logs, metrics, traces, and dashboards appear automatically for any service deployed via the paved road. The OpenTelemetry project's semantic conventions make this dramatically easier than it was three years ago, and platform teams that have not adopted them are creating future migration debt.
- Secrets and identity management that do not require a ticket. Self-service with audit, not gatekeeping. Workload identity federation, short-lived credentials, and policy-as-code beat human approval workflows on every dimension that matters.
- Cost and quota visibility. Per-service, per-team, in the same place engineers already look. FinOps Foundation surveys consistently show that engineers will optimize cost when they can see it attributed to their service in near-real time, and ignore it when the data lives in a finance dashboard they never open.
- Service catalog and ownership metadata. Backstage is the de facto here, but it is the last layer to build, not the first. A catalog of services nobody can deploy is a museum.
Teams that try to build all six in parallel deliver none of them well. The teams that succeed sequence them, usually starting with provisioning and CI/CD, then layering observability, then secrets and cost, with the catalog as a unifying surface once the underlying capabilities are stable. We typically see a 12 to 18 month build to get all six to a credible state, with the first paved road in production around month four.
Staffing and structure
The platform team that succeeds is built like a product team: a product manager, designers, software engineers, and SREs, not a rebadged operations team. The team is small (six to twelve engineers for a mid-large enterprise), reports into engineering rather than IT, and has a budget independent of any individual customer team.
The product manager is the role most often missed. Platform PMs are rare and the hiring market for them is thin, but the alternative, a tech lead doubling as PM, almost always reverts to building what is technically interesting rather than what is most adopted. Designers are the second most often missed. A platform UI designed by engineers for engineers is a recognizable artifact: dense, terminology-heavy, with no onboarding flow and no empty states. Engineers will tolerate it, but tolerance is not adoption.
On reporting lines, we hold a contrarian view: the platform team should report to a senior engineering leader who has product responsibility, not to a CIO or head of infrastructure. The CIO org is structurally optimized for cost control and risk reduction, both of which are corrosive to a product team's willingness to ship and iterate. We've seen platform teams under infrastructure leadership measure themselves on uptime and ticket volume, both of which can improve while adoption craters.
Funding and the chargeback question
A related question we get often: should the platform charge back to consuming teams? Our default answer is no, at least for the first two years. Chargeback creates a procurement dynamic that slows adoption precisely when adoption is the goal, and it gives consuming teams a reason to build their own thing to escape the cross-charge. Fund the platform centrally, measure it on adoption and developer-experience outcomes, and revisit chargeback only once it is clearly the default path.
The exception is cloud cost itself, which should always be transparently attributed to the consuming service. The platform's own labor cost is the part that should not be cross-charged in the early years.
What to expect at twelve months
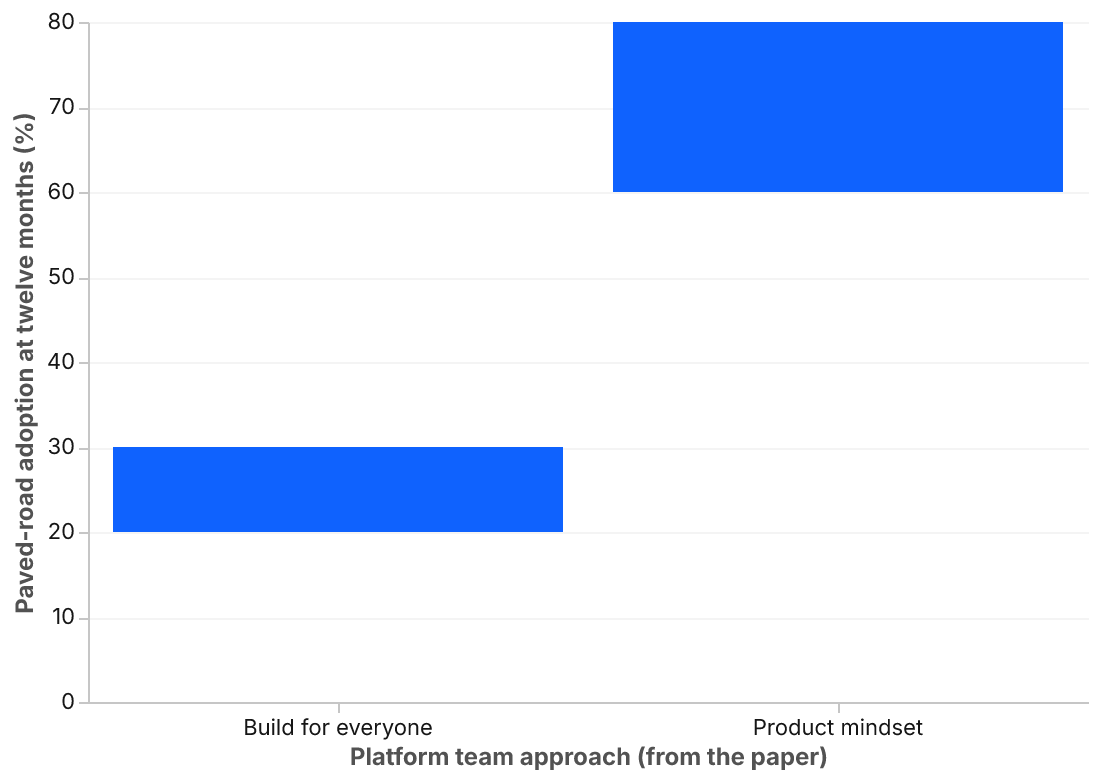
A platform team running with a product mindset and disciplined sequencing typically reaches 60 to 80 percent paved-road adoption for new services within a year, with measurable improvements in deploy frequency, lead time, and incident MTTR. The same team trying to build for everyone reaches 20 to 30 percent and stalls.
The leading indicator we watch most closely is not adoption but _voluntary_ adoption: the percentage of new services that chose the paved road when an exception was readily available. If that number is above 70 percent, the platform is winning on merit. If it is below 40 percent and the headline adoption number is high, the platform is winning on policy, and the policy will eventually be relaxed by an executive who hears one too many complaints at a skip-level.
Existing services are a separate question. Migration of legacy services onto the platform is almost always slower and more expensive than expected, and we generally counsel clients not to mandate it. Let the paved road win on new work first. Migration becomes tractable, and sometimes voluntary, once the productivity delta is undeniable.
The bottom line
Platforms are not built; they are adopted. The technical work is rarely the hard part. The hard part is treating engineers as users whose time you must earn, every release, on the merits of what you ship. The teams that internalize this run their platforms like products, sequence their capabilities, staff for design and product management as well as engineering, and resist the temptation to declare victory based on mandated usage.
The teams that don't end up with a portal nobody loves, a backlog nobody can clear, and a quiet conversation eighteen months in about whether the whole thing should be rebooted under new leadership. That conversation is avoidable. It just requires accepting, on day one, that your engineers are customers and that customers cannot be ordered to be satisfied.